
Come lavora un data journalist
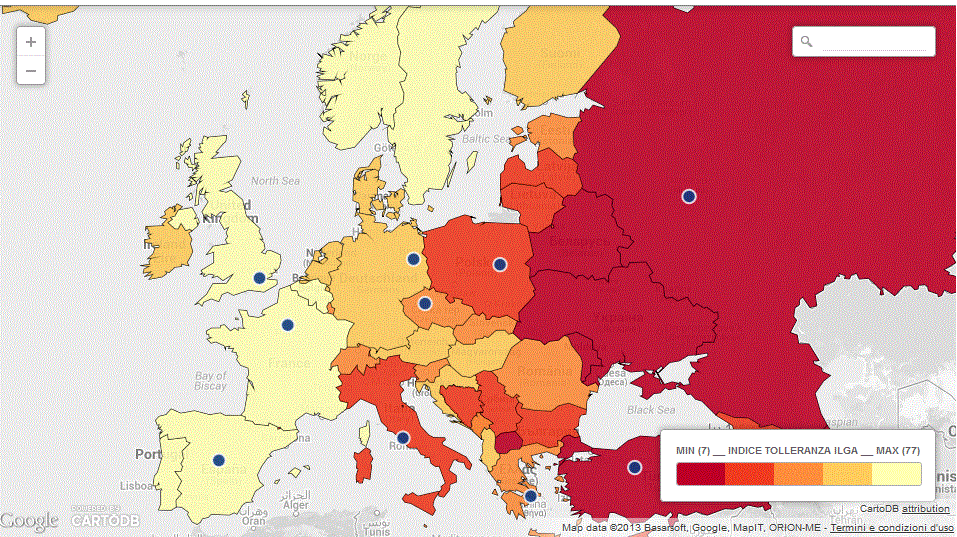
 Qualche giorno fa Il Fatto.it ha pubblicato una inchiesta sulla omofobia in Europa e in Italia realizzata da Jacopo Ottaviani.
Qualche giorno fa Il Fatto.it ha pubblicato una inchiesta sulla omofobia in Europa e in Italia realizzata da Jacopo Ottaviani.
Si tratta di un bel lavoro di data journalism (il giornalismo basato sui dati), realizzato attraverso l’ individuazione, l’ elaborazione e la visualizzazione di una serie di dati raccolti da varie fonti: in questo caso, soprattutto ILGA Europe, Pew Research Center (“The Global Divide on Homosexuality”) e Istat.
L’ inchiesta ha messo in luce come il nostro paese presenti il più alto tasso di discriminazione in Europa in termini di politiche dei diritti Lgbt, ma sia anche quello che mostra il maggiore aumento di tolleranza nei confronti degli omosessuali.
Ottaviani – che partecipa al gruppo ‘’Datajournalismitaly’’ – racconta a Lsdi come ha realizzato questa inchiesta e fa capire come lavora concretamente un data journalist.
 Dalle fonti alla visualizzazione, spunti e strumenti
Dalle fonti alla visualizzazione, spunti e strumenti
di Jacopo Ottaviani
Ho fatto tutto il lavoro da solo, dalla raccolta dati allo sviluppo finale.
Semplificando molto, di solito lavoro così: trovo un argomento interessante e comincio a cercare dati a riguardo. Gli argomenti sono infiniti: tutto, se visto in un’ ottica data-driven, nasconde un potenziale giornalistico a patto che ci siano dati appetibili sul tema. Inoltre, ad oggi, in Italia, quasi niente è stato ancora sviluppato attraverso le tecniche proprie del data journalism.
Trovati i dataset, ne va fatta una cernita: quali possono rispondere alle nostre domande? Come fare? E come sono stati costruiti?
Quest’ ultima questione è fondamentale perché “dato” è tutto fuorché sinonimo di verità. Sono molto importanti le note metodologiche allegate a ogni studio che possa considerarsi tale: su quelle si trovano informazioni, ad esempio, sulla composizione del campione preso in analisi. Più si è severi nella selezione delle fonti, meno si rischia di mal rappresentare la realtà. In generale, è bene saperne un po’ di statistica e di scienze sociali.
Trovati i dati e appurata la qualità e l’ usabilità, si passa alla loro elaborazione.
Incrocio, selezione, unione. Un lavoro di falegnameria che richiede molta pazienza.
Software utili in questa fase possono essere, per esempio, Excel e OpenRefine (ex Google Refine).
Questa fase è più lunga se i dati non si presentano in formato aperto (ovvero, per esempio, CSV o JSON – formati che spopolano tra le istituzioni dei paesi anglosassoni, mentre da noi ancora si predilige il PDF).
Ancora più complicate le cose sono se il dataset va strutturato attraverso una fase di scraping (letteralmente ‘raschiatura’: il termine nel gergo del data journalism indica la raccolta di dati dispersi fra vari materiali documentari, ndr) e questo richiede la programmazione di uno script (un tipo di programmi particolari, ndr), ad esempio con ScraperWiki (https://scraperwiki.com/ ).

La fase dell’ elaborazione si fa già tenendo a mente come si intende procedere nella fase successiva, ovvero quella della visualizzazione, e in base a ciò si rimodellano i dataset per essere affidati al nostro tool di visualizzazione.
Dietro alla data visualization c’è tutta una scienza, come ci mostrano Giulio Frigieri sul blog civicinforgraphics della Fondazione Ahref o Paolo Ciuccarelli con i suoi progetti del Density Design. Per farsi un’ idea concreta su come si possono visualizzare i dati sul web si può consultare la famosa selezione di datavisualization.ch che riporta molti degli strumenti e delle ‘’librerie’’ di data visualization più famose.
Ultimamente – ma le cose cambiano molto in fretta – i tool che prediligo, in ordine di difficoltà d’ uso: DataWrapper.de (per diagrammi), CartoDB (per le mappe) e d3js per visualizzazioni più complesse. Saper programmare è d’ obbligo se si intende fare qualcosa con tecnologie più avanzate come d3js, mentre non è indispensabile per tool come DataWrapper e CartoDB.
Per l’ inchiesta sull’omofobia in Europa uscita per il Fatto, in particolare, ho usato DataWrapper e CartoDB basandomi su tre fonti di dati: Pew Research Institute, Ilga Europe e ISTAT.
Ciascuna delle fonti rispondeva a domande distinte che nel complesso avrebbero portato a una conclusione: dati alla mano, l’opinione pubblica italiana si sta aprendo all’accettazione dell’omosessualità a una velocità che non sembra essere colta dalla politica.